A Leaderboard for Grounded Factuality ✅

Can an LLM be used to fact-check the output of another LLM? The LLM-AggreFact dataset, introduced in our paper MiniCheck, tests LLMs' ability to assess grounded factuality, or whether statements are supported by evidence documents. We are now releasing the leaderboard, with a new dataset since the release of the original paper, to track how well LLMs can fact-check LLM-generated content.
✨NEW✨ results including Llama-3.1, Mistral 2, Claude-3.5 Sonnet, and a new SOTA model Bespoke-Minicheck-7B from Bespoke Labs.
✨NEW✨ Demo of Bespoke-Minicheck-7B with real-time inference.
Grounded Factuality: What LLM-AggreFact performance means
"Hallucination" is used to refer to many types of errors in LLM responses. Here we are interested in grounded factuality: Assuming that we are given a context paragraph and a statement, we want to check if that statement is logically supported by the context (aka grounding documents). One key type of error is when a model fails to accurately reflect information given in its context and produces an answer with hallucinations. The MiniCheck paper calls this fact-checking on grounding documents.
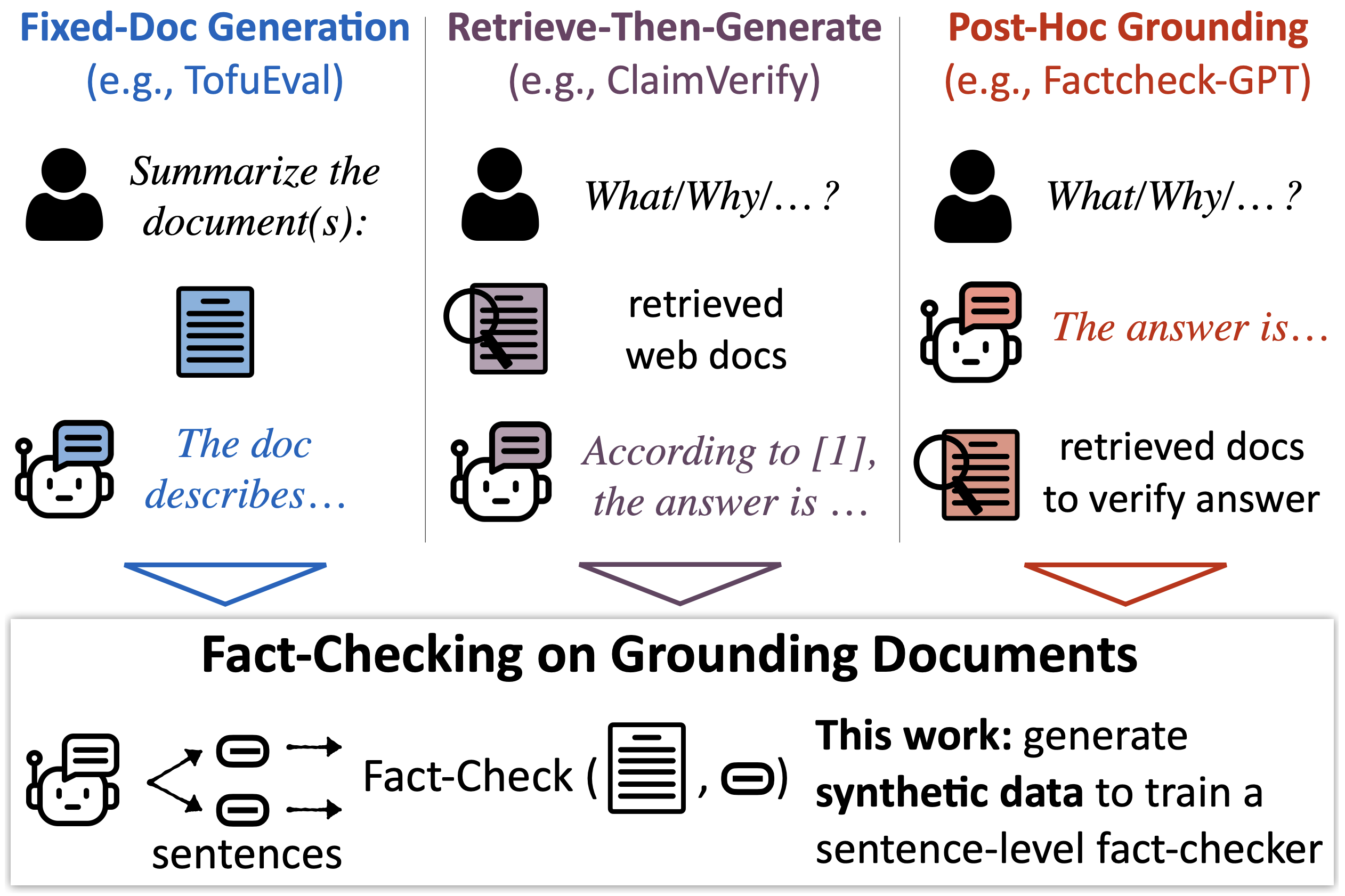
This is a very fundamental capability that is needed for retrieval-augmented generation (RAG) and related problems like summarization and document-grounded question answering.
LLM-AggreFact draws together performance across 11 datasets, all with the format: ({D}, c, y), where {D} is a grounding document set, c is a claim, and y is a boolean label to indicate whether c is supported by {D}.
There are two general approaches to this task. First, LLMs can be prompted zero-shot with the document(s) and the claim, and asked if the claim is supported by the document(s). Second, models designed for related subtasks like textual entailment or question answering (or multitasked models, like AlignScore) can be used to produce classification decisions. MiniCheck belongs to the second approach.
Datasets included in the LLM-AggreFact Benchmark
- Summarization datasets (AggreFact-CNN/XSum, TofuEval-MeetB/MediaS, RAGTruth): datasets of models trained or prompted for summarizing documents, meeting transcripts, etc.
- Retrieval-augmented generation datasets (ClaimVerify, LFQA, ExpertQA, RAGTruth): datasets of models answering questions from retrieved documents.
- Post-hoc grounding (ExpertQA, REVEAL, Factcheck-GPT): datasets where models' answers are generated "closed book", then verified against retrieved documents.
- Human-written claims (WiCE): Wikipedia claims with citations.
All of these datasets are labeled for factuality by expert annotators. This is an up-to-date collection of high-quality labeled datasets over strong LLM outputs. The MiniCheck paper further discusses the rationale for including or excluding different benchmarks.
Cost Considerations
We think it's important for LLM fact-checkers to be small and cheap to run. A response from an LLM might consist of many sentences. To identify and localize errors, a fact-checker needs to be called many times. If we use GPT-4 as the fact-checker, we can easily spend >10x more to verify the response than we did to produce it in the first place!
The leaderboard also includes model size as a key factor. For most models, this correlates with FLOPs and cost in a standard way. However, this is a stark divide between open-source models and closed-source models. Fact-checking the examples in the benchmark can cost as much as $100 when using GPT-4, but as little as $1 when using smaller models hosted on premise. We hope to provide guidance to practitioners about what models perform well across different scales.
(More detail on cost is available in the MiniCheck paper.)
How do models do?
Among LLMs, more recent and larger-scale models typically perform better. Notably, Mistral-Large 2 and Claude-3.5 Sonnet outperform the latest GPT-4 variants and Llama-3.1-70B Instruct is also a strong off-the-shelf open model.
Bespoke-Minicheck-7B: The best performance on our leaderboard comes from a 7B model that was created using a proprietary data curation process from Bespoke Labs. In contrast to other MiniCheck models in the paper, Bespoke-Minicheck-7B was trained using synthetic data from Llama-3.1-405B which is the strongest open model available for commercial use. Surprisingly, it outperforms much bigger models demonstrating that the data curation process is the key for small model performance.
Bespoke-Minicheck-7B is available as a demo here.
Benchmark and Contribute: Please use this colab to evaluate your model on the LLM-AggreFact benchmark and let us know by opening a PR at the MiniCheck github repo or send an email here.
Conclusion and Future Work
We are eager to see more progress in small, faster, and more performant models for this kind of fact-checking. We will be actively maintaining this leaderboard; if you wish to add your model to it, please get in touch with us.
Caveats: Systems on this leaderboard are benchmarked in a zero-shot fashion. As this is a binary classification task, it is possible to tune the threshold for each dataset. We believe this should be explored in practice. The MiniCheck paper shows that slightly stronger results can be achieved by doing this, but frontier LLMs do not benefit much.
Furthermore, note that this task involves detecting hallucinations, but is not the only phenomenon referred to as such. A significant body of work is concerned with whether LLMs output the right answers about long-tail entities when prompted "closed book", e.g., FActScore and the recent WildHallucinations. This is not our focus.